Run AI Completely Offline with Ollama and GPT-OSS - Part 1
Last week I showed you how to set up your own private ChatGPT with LibreChat and Gemini. That still needed an internet connection for the API calls.
Today we're going completely offline. No internet, no API keys, no external servers. Just you, your computer, and OpenAI's new open-source model running locally.

What You'll Build
You'll set up Ollama with OpenAI's gpt-oss model - their first open-weight reasoning model. You'll get:
Completely offline AI that works without internet
OpenAI-quality reasoning and chain-of-thought
Full control over your data and conversations
Function calling and code execution capabilities
No usage limits or token counting
Apache 2.0 license for commercial use
Setup takes 20 minutes. Your conversations never leave your computer.
Why GPT-OSS?
Simple reasons:
It's from OpenAI, so you know the quality is there
Designed for reasoning tasks with full chain-of-thought
Open-weight under Apache 2.0 license
Works completely offline
Can run on consumer hardware (16GB+ RAM)
Has agentic capabilities built in
What You Need
Check you have these:
A computer with 16GB+ RAM (20B model) or 80GB+ for the larger model
About 20GB free disk space
20 minutes
No internet connection required after setup
System Requirements
For gpt-oss:20b (smaller model):
16GB RAM minimum
14GB disk space
Any modern CPU
For gpt-oss:120b (larger model):
80GB RAM or GPU memory
100GB+ disk space
High-end hardware
Most people should start with the 20B model.
Step 1: Install Ollama
Windows:
Go to ollama.com
Download Ollama for Windows
Run the installer
Open Command Prompt
Mac:
Go to ollama.com
Download Ollama for Mac
Install like any Mac app
Open Terminal
Linux:
curl -fsSL https://ollama.com/install.sh | sh
Step 2: Download GPT-OSS
This is the easy part. One command downloads everything:
ollama pull gpt-oss:20b
This downloads about 14GB. It takes a while but only happens once.
For the larger model (if you have the hardware):
ollama pull gpt-oss:120b
Step 3: Run It
Start chatting:
ollama run gpt-oss:20b
You'll see:
>>> Send a message (/? for help)
Type: "Hello, can you explain what makes you different from other AI models?"
You should get a detailed response with reasoning. The model shows its thinking process, which is pretty cool.
Sample output:

Step 4: Test the Reasoning
Try this prompt to see the chain-of-thought in action:
Solve this step by step: If I have 15 apples and give away 1/3 of them, then buy 8 more apples, how many apples do I have total?
Watch how it breaks down the problem and shows each step.
Using It as an API Server
You can also run Ollama as an API server for other applications:
ollama serve
This starts a server at http://localhost:11434 that's compatible with OpenAI's API format.
Test it with a simple Python script. Create test.py:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # dummy key
)
response = client.chat.completions.create(
model="gpt-oss:20b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in simple terms."}
]
)
print(response.choices[0].message.content)
Run it:
# Create and activate virtual environment
python -m venv ollama-env
# Windows activation
ollama-env\Scripts\activate
# Mac/Linux activation
source ollama-env/bin/activate
# Install dependencies
pip install openai
# Run your scripts
python test.py
Sample output:

Advanced Features
GPT-OSS has built-in capabilities that most local models don't have:
Function Calling:
GPT-OSS can understand when to call functions, but since it's offline, you need to implement the actual functions yourself. Here's how it works:
# First, make sure your virtual environment is active
# Windows: ollama-env\Scripts\activate
# Mac/Linux: source ollama-env/bin/activate
tools = [
{
"type": "function",
"function": {
"name": "calculate_math",
"description": "Calculate a mathematical expression",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}},
"required": ["expression"]
}
}
}
]
response = client.chat.completions.create(
model="gpt-oss:20b",
messages=[{"role": "user", "content": "What's 15 * 23 + 7?"}],
tools=tools
)
# The model will return a tool call like:
# [ChatCompletionMessageToolCall(id='call_123', function=Function(arguments='{"expression":"15 * 23 + 7"}', name='calculate_math'), type='function')]
if response.choices[0].message.tool_calls:
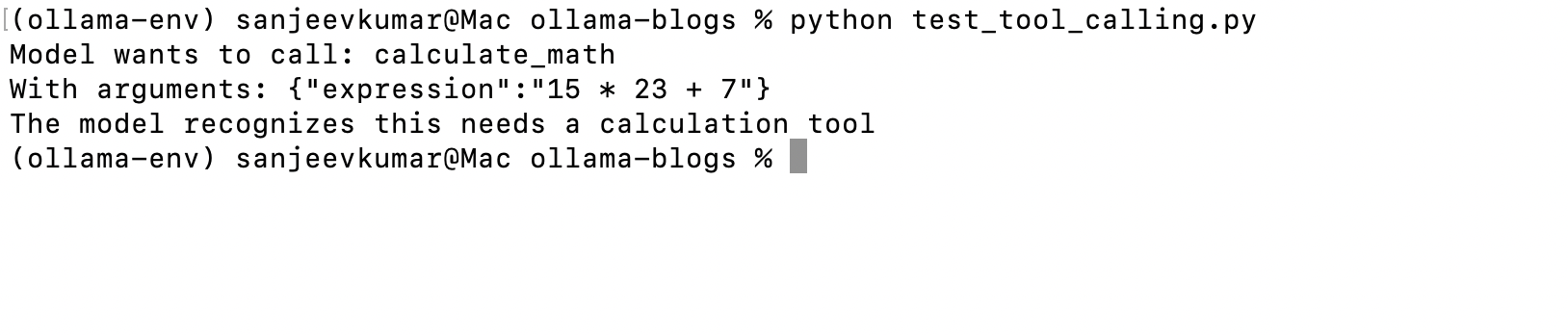
tool_call = response.choices[0].message.tool_calls[0]
print(f"Model wants to call: {tool_call.function.name}")
print(f"With arguments: {tool_call.function.arguments}")
# You'd implement the actual calculation here
# result = eval(tool_call.function.arguments) # Don't use eval in real code!
print("The model recognizes this needs a calculation tool")
else:
print(response.choices[0].message.content)
This shows the model can identify when tools are needed, but you need to implement the actual functionality.
Configurable Reasoning: You can adjust how much the model "thinks" before responding:
import json
import re
from openai import OpenAI
# Initialize client
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama"
)
def safe_calculate(expression):
"""Safely calculate basic math expressions"""
# Only allow numbers, operators, parentheses, and spaces
if re.match(r'^[0-9+\-*/().\s]+
**Configurable Reasoning:**
GPT-OSS can adjust how much it "thinks" before responding. You control this through the system message:
```python
# For quick responses
quick_system = "You are a helpful assistant. Reasoning: low. Provide fast, direct answers."
# For balanced thinking
balanced_system = "You are a helpful assistant. Reasoning: medium. Balance speed with thorough analysis."
# For deep analysis
thorough_system = "You are a helpful assistant. Reasoning: high. Think through problems step-by-step with detailed analysis."
# Example usage
response = client.chat.completions.create(
model="gpt-oss:20b",
messages=[
{"role": "system", "content": thorough_system},
{"role": "user", "content": "Explain why the sky is blue"}
]
)Reasoning levels:
Low: Fast responses for simple questions
Medium: Balanced thinking and speed
High: Deep reasoning for complex problems
You can also hide the reasoning process from users:
hide_reasoning_system = "You are a helpful assistant. Do not show your thinking or reasoning process in your response - only provide the final answer."If Something Goes Wrong
Model won't download:
Check you have enough disk space (20GB+)
Try again - sometimes downloads fail
Use
ollama pull gpt-oss:20b --verbosefor more info
Out of memory errors:
Close other applications
Try restarting your computer
Make sure you have 16GB+ RAM
Ollama won't start:
Check if it's already running:
ps aux | grep ollamaKill existing process:
pkill ollamaStart fresh:
ollama serve
Slow responses:
This is normal for the first few messages
Responses get faster as the model warms up
Close other heavy applications
Performance Tips
Speed up responses:
Use SSD storage if possible
Close unnecessary applications
Let the model warm up with a few test messages
Better quality:
Give more context in your prompts
Use system messages to set behavior
Be specific about what you want
Managing Models
See all installed models:
ollama list
Remove a model to free space:
ollama rm gpt-oss:20b
Update Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Stop Ollama:
pkill ollama
Try Other Models
Want to compare different models? Try these:
# Meta's latest model
ollama pull llama3.2
# QWEN model
ollama pull qwen3:30b
# Compare them
ollama run llama3.2 # In Terminal 1
ollama run qwen3:30b # In Terminal 2
ollama run gpt-oss:20b # In Terminal 3
Each has different strengths. GPT-OSS excels at reasoning and function calling.
What Now?
You have a completely offline AI that:
Never sends data anywhere
Works without internet
Has OpenAI-level reasoning
Runs on your hardware
Costs nothing to use
Try asking it to:
Debug code and explain the fixes
Solve math problems step-by-step
Write and explain Python scripts
Analyze text you paste in
Basic Commands Reference
# Download a model
ollama pull gpt-oss:20b
# Run interactive chat
ollama run gpt-oss:20b
# Start API server
ollama serve
# List models
ollama list
# Remove model
ollama rm gpt-oss:20b
# Stop ollama
pkill ollama
Get Help
Ollama Discord: discord.gg/ollama
GPT-OSS GitHub: github.com/openai/gpt-oss
Ollama Issues: github.com/ollama/ollama/issues
Next: Connect your offline AI to LibreChat for a full ChatGPT-like interface with advanced features.